6 minutes
Raytracer 4: SIMD
NOTE: This is my first real experience with SIMD. So whatever I do next, might be completely stupid and wrong! This is a learning exercise for me! So, yeah.
The last post, we implement multithreading on the raytracer and we get nearly 2.5x performance boost up. There is another parallelism technique called SIMD. I'm going to try to implement in the raytracer. But first, let's measure our program.
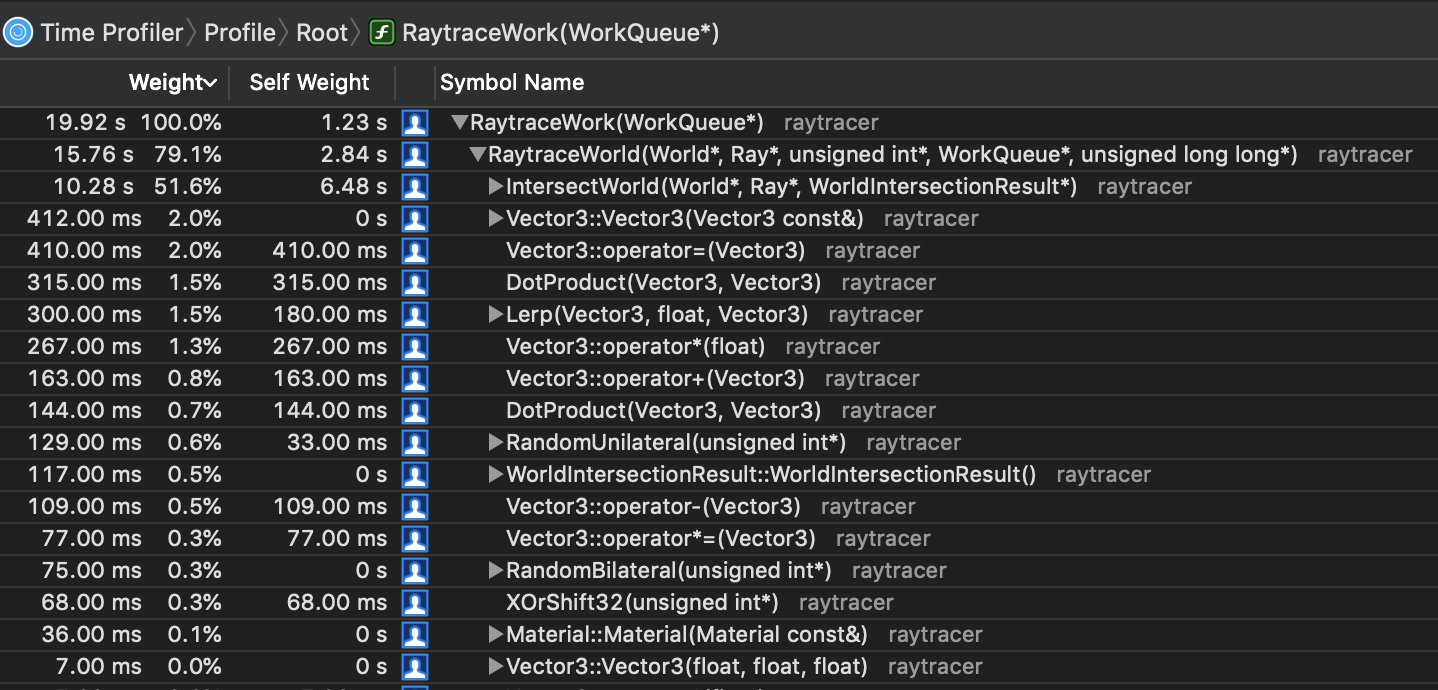
As you can see the image above, the program spends half of his time on intersection checking. So it's a smart idea that starting simd optimization on intersection checking first.
What is SIMD
SIMD stands for "Single Instruction Multiple Data". I think SIMD basically viewed as operations on arrays. For example, instead of adding single float to another single float and get a single float result, you add elements of a float array to another float array then get a float array result.
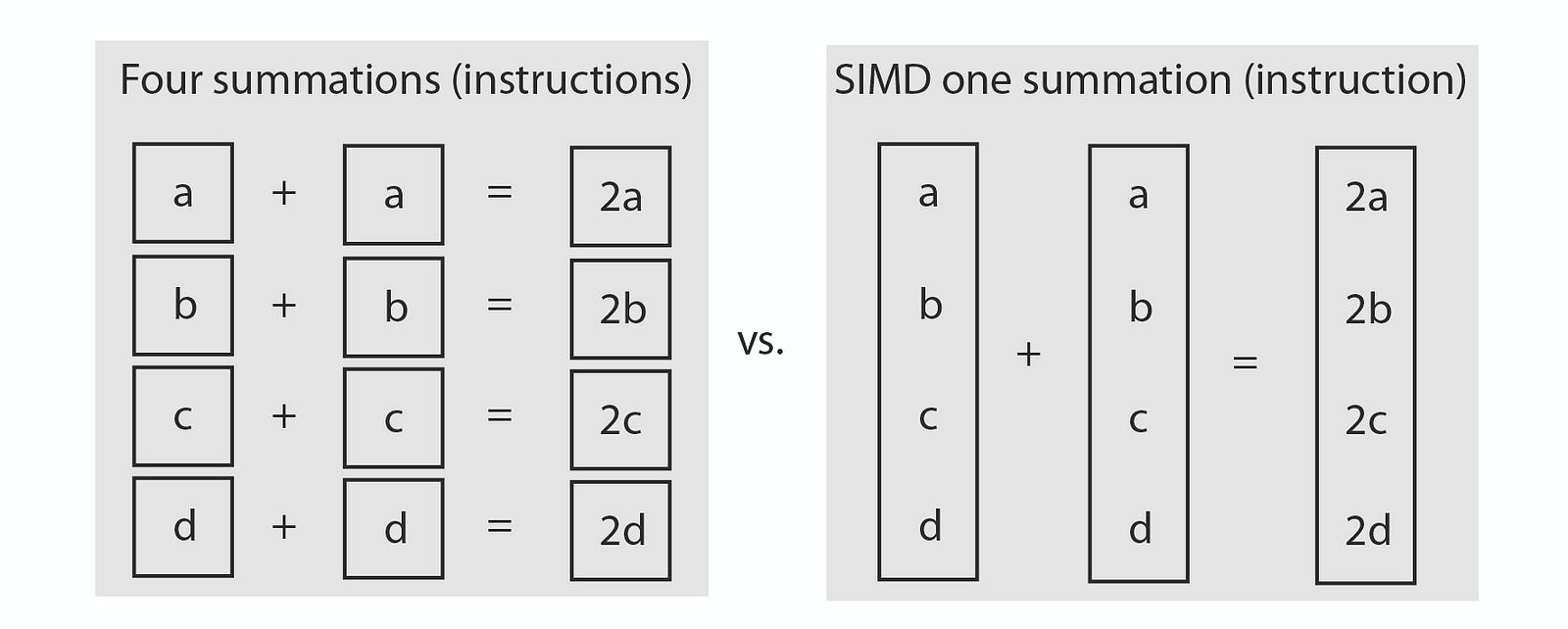
This image (which taken from here) clearly shows what's happening. On the left, we use single float type and make 4 additions to get results that we want. On the right, 4-length arrays adding in single add operations and we get all result in 4-length array.
The problem is: How we are gonna modify our code to get performance benefits of SIMD?
IntersectWorldWide
In the IntersectWorld function, we test every ray for if it has collision to scene objects.
We have 1 plane in our scene, so that should be remain scalar. Most of the work is doing
on sphere intersection checking. Since we have more than 1 spheres, we could try to check multiple spheres at once.
For that, we need to store spheres into more SIMD friendly shape. We need to put members into arrays. SoA (Structure of Arrays) layout is good for this. Instead of layout the sphere classic way, we can layout this way:
struct SphereWide {
float sphereX[N];
float sphereY[N];
float sphereZ[N];
float radius[N];
uint32_t hitMaterialIndex[N];
};
The SoA layout is very helpful when you only need one or two members of struct cases. Because of every member are arrays, cache line fills with relevant data, not the data we don't use. That gives a huge performance boost. A good example of this problem shown here.
But in our case, we always use every member of Sphere in function. So we need something in between.
And that is called AoSoA layout.
It's like fixed SoA layout. Members are still arrays but array size equal to SIMD vector size.
If your sphere size greater than LANE_WIDTH, you add another sphere lane into sphereLaneArray.
That way we can perfectly store spheres into SIMD registers.
struct SphereLane {
float sphereX[LANE_WIDTH];
float sphereY[LANE_WIDTH];
float sphereZ[LANE_WIDTH];
float radius[LANE_WIDTH];
uint32_t hitMaterialIndex[LANE_WIDTH];
};
SphereLane sphereLaneArray[sphereLaneArrayCount];
When you put your data in the right shape, the rest of the problem is easy. We almost use the exactly same code for sphere intersection but with wide variable types.
// Broadcast scalar values into lanes.
LaneVector3 rayOrigin(ray->origin);
LaneVector3 rayDirection(ray->direction);
for (int sphereLaneIndex = 0; sphereLaneIndex < world->sphereSoAArrayCount; ++sphereLaneIndex) {
SphereSoALane sphereSoA = world->sphereSoAArray[sphereLaneIndex];
...
Intersection code in wide
...
}
// To make horizontal check operations on lanes, we store them into scalar float array
// And iterate over them. This is the complexity comes with SIMD.
if (anyHit) {
// After calculating n sphere ray intersection, we have to find which one is closer.
// This is probably the most naive way to do it. We store lane values into an array and iterating through to find any close hit.
ALIGN_LANE float closestHitDistanceLaneArray[LANE_WIDTH];
ALIGN_LANE float hitMaterialIndexLaneArray[LANE_WIDTH];
ALIGN_LANE float hitNormalLaneXArray[LANE_WIDTH];
ALIGN_LANE float hitNormalLaneYArray[LANE_WIDTH];
ALIGN_LANE float hitNormalLaneZArray[LANE_WIDTH];
StoreLane(closestHitDistanceLaneArray, closestHitDistanceLane);
StoreLane(hitMaterialIndexLaneArray, hitMaterialIndexLane);
StoreLane(hitNormalLaneXArray, hitNormalLane.x);
StoreLane(hitNormalLaneYArray, hitNormalLane.y);
StoreLane(hitNormalLaneZArray, hitNormalLane.z);
for (int i = 0; i < LANE_WIDTH; ++i) {
float t = closestHitDistanceLaneArray[i];
if (t < closestHitDistance) {
closestHitDistance = t;
hitMaterialIndex = hitMaterialIndexLaneArray[i];
hitNormal = Vector3(hitNormalLaneXArray[i],
hitNormalLaneYArray[i],
hitNormalLaneZArray[i]);
}
}
}
Let's measure our code with SIMD operations:
- Before SIMD: 49.2 Mray/s, 0.000020 ms/ray
- After SIMD: 54.8Mray/s, 0.000018ms/ray
We get a speed-up with 4-wide SSE operations but not too much. Where is the 4x?
Amdahl's Law
There is an Amdahl's Law. Which tells us; the speedup gain from parallelization depends on how much of your program can be parallelized.
The program was spending %50 of its execution time in IntersectWorld function.
As you can see image above; no matter how many processors, how many lanes you use,
we can't get over 2x. This is one of the primary reason why we are not getting 4x speedup
with 4-lane vectorization.
Compiler switches
Most of the graphics programs I've seen use -ffast-math settings.
So I gave a try for it. And I get same speed with clang compiler on my machine.
Fast math doesn't give too much on clang. Let's try with GCC.
- Clang
-O2: 54.8Mray/s, 0.000018ms/ray - Clang
-O2 -ffast-math: 54.8Mray/s, 0.000018ms/ray (It's roughly the same performance with fast math) - GCC
-O2: 63.2Mray/s, 0.000016ms/ray (It's already faster than clang without fast math) - GCC
-O2 -ffast-math: 65.6Mray/s, 0.000015ms/ray (Fast math doing something on GCC)
I used -msse4.1 switch for enabling SSE instructions. My CPU supports 8-wide AVX2 instructions
so we can enable these instructions with -mavx2 flag. So with the 4-wide SSE, we can
check intersection with 4 spheres at the same time. With AVX2, we can check 8 spheres. But our scene
only contains 4 spheres now. So we are not gaining performance from AVX2.
And there is another flag called -march=native. Which uses all CPU capabilities
and generate optimized code for that CPU. After compiling with native flag our performance
up to 75.3Mray/s, 0.000013ms/ray. Wow!! That's an unexpected performance gain.
But how? Let's look at the assembly code.

The only difference I see between -mavx2 and -march=native are those weird
## FMA Instruction Set
Apparently, there is an instruction set called [FMA](https://en.wikipedia.org/wiki/FMA_instruction_set).
This instruction set, allows you to perform multiply and add operations in one instruction.
Compiler optimized some code with FMA operations already. Bu we can manually write FMA
operations with [intrinsics](https://software.intel.com/sites/landingpage/IntrinsicsGuide/#techs=FMA).c++ inline LaneF32 FMulAdd(const LaneF32 left, const LaneF32 right, const LaneF32 addend) { LaneF32 result; #ifdef FMA result.m = _mm256_fmadd_ps(left.m, right.m, addend.m); #else result = (left * right) + addend; #endif
return result;};
We can implement DotProduct with FMA operations like this:c++ inline LaneF32 DotProduct(const LaneVector3 left, const LaneVector3 right) { return FMulAdd(left.x, right.x, FMulAdd(left.y, right.y, (left.z * right.z))); }; ```
After converting one or two operations to FMA operations, performance stays the same as before.
This is because when we compiled our program with -march=native flag, the compiler converted to
all dot products to FMA instructions. That's why we got such a performance improvement.
But making manually is good too. You know what you getting. FMA commit is here.
Learnings
- If you use correct memory layouts when implementing SIMD, the rest of the problems solves itself.
- Parallel performance heavily depends on how much of your program parallelized.
- Compiling code with
-march=nativeflag produces efficient code on your CPU.
I won't parallelize more program for now. I think its time to implement rendering techniques instead of optimizing.
1175 Words
2019-04-30 17:29 +0300