5 minutes
Raytracer 3: Multithreading
Last post, we implemented a custom random number generator. And we got 21.0 Mray/s, 0.000048 ms/ray on my laptop. So lets try to improve performance more.
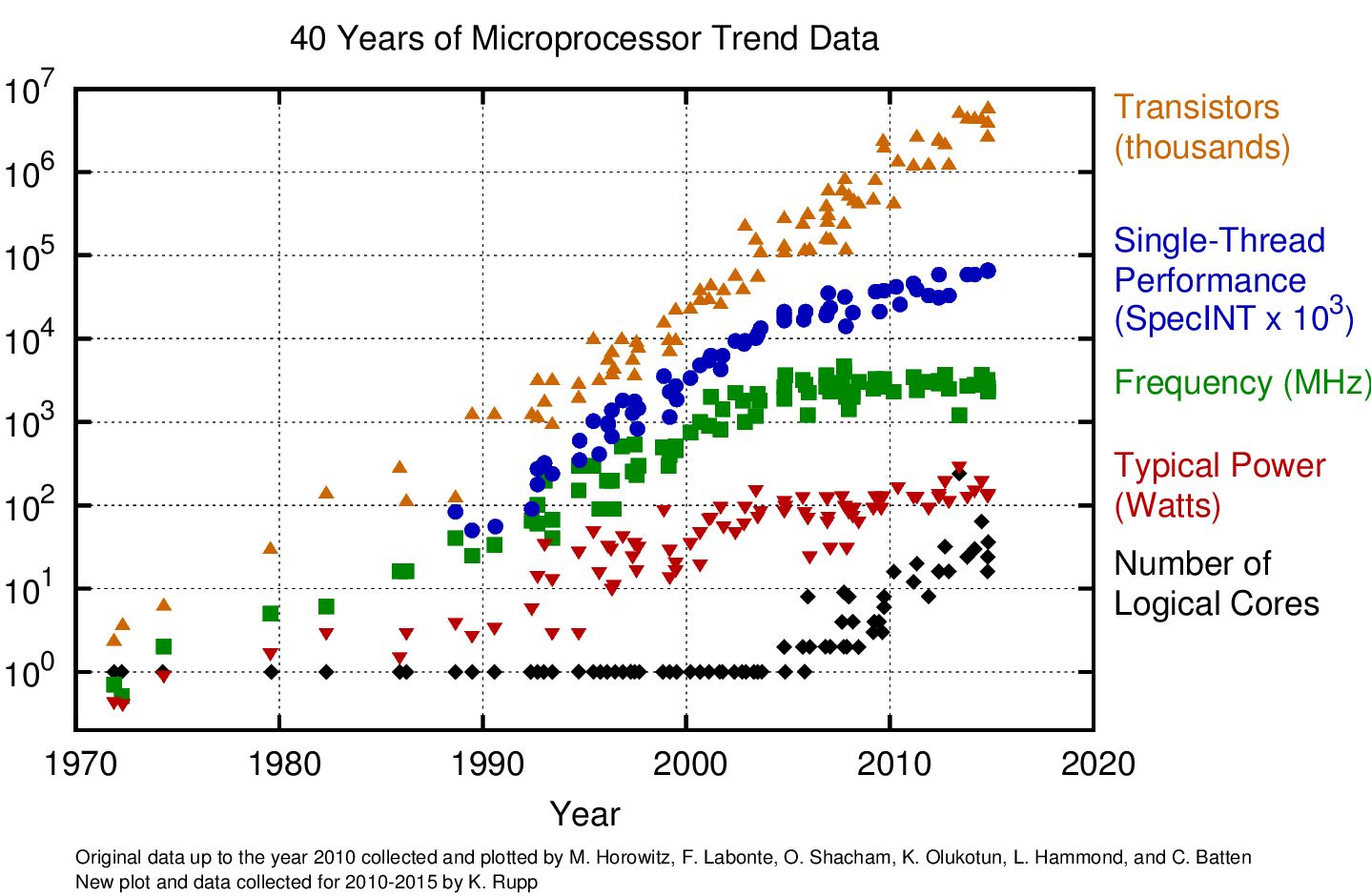
You might have seen this famous image before which taken from here. What this image tells us is that even transistor count still increasing linearly, processors not getting faster anymore like used to be. But on the other hand, when the single threaded performance speed of acceleration starts to drop, the number of logical core count begins to increase.
So the lesson I got here is that if you write a single-threaded program, you will not get much a performance on new processors. You need to use cpu cores to get much more performance on new processors. That's what I'm gonna try to do right now.
Utilizing the CPU cores
For utilizing CPU threads, we need some way to break our program into pieces. And that's a very hard problem. If you figure out how to break your program into pieces, then you have to figure out how to synchronize them. But we are lucky! Raytracer is easily breakable into chunks. We are calculating image pixels. And every pixel independent to others. We won't have much trouble with synchronization. The cores going to render image pixels with independent to others. After finishing all the pixels, we going to write the output image.
"Lock-free" programming
I read a document about lockless programming. It's talk about problems about multithreading, how compilers and processors behave, how console CPUs differs from PC CPUs, etc. It's talk about around Windows API but all of the things are valid in other platforms too. I want to implement multithreading using atomics for synchronization so that threads not will be blocked. It's generally easier using locks instead of atomic instructions like document says. But I think in this project, atomic instructions will not be that hard. So I will give a shot.
Implementing
Let's try to divide our program into pieces. My laptop has 4 threads. If we can divide image to thread count and give each thread a piece, we can render image 4 times faster, right? Umm, sadly no! As you can see in the image below, if we divide image to the thread count, thread 2, will do the most part of the work, and thread 1, 3, 4 will wait for the thread 2 after finishing its job. This is not efficient and it's almost same as using single-thread in this case.

So how do we divide work evenly to all threads? The answer is simple. We divide the image into more parts. All threads execute its task and switch to other tasks in the work queue immediately. So that way if a thread gets a long-running job, other threads will be busy for executing other jobs. A good visual explanation for this problem is here.
For the implementing first I created a thread for every row on the image.
Then I used Apple GCD.
You can easily multithread your loop using the dispatch_apply function.
It uses all threads and waits all to be finished. So there is no need for synchronization.
GCD automatically does for us. It is a really easy and perfect fit for our program.
You can see the GCD implementation here.
But I ended up using a simple work queue method from Handmade Ray. We create work orders and put them into a queue. Then every thread looping through the queue and executing waiting jobs. If there is no job to be executed, we release the thread. I think it's a easy, understandable and flexible method.
struct WorkOrder {
Image* image;
World* world;
uint32_t startRowIndex;
uint32_t endRowIndex;
uint32_t sampleSize;
uint32_t* randomState;
};
struct WorkQueue {
uint32_t workOrderCount;
WorkOrder* workOrders;
volatile uint64_t nextOrderToDo;
volatile uint64_t finishedOrderCount;
volatile uint64_t totalBouncesComputed;
};
bool RaytraceWork(WorkQueue* workQueue) {
uint32_t nextOrderToDo = InterlockedAddAndReturnPrevious(&workQueue->nextOrderToDo, 1);
if (nextOrderToDo >= workQueue->workOrderCount) {
return false;
}
fetch the next WorkOrder
...
do the raytracing
...
InterlockedAddAndReturnPrevious(&workQueue->totalBouncesComputed, totalBounces);
InterlockedAddAndReturnPrevious(&workQueue->finishedOrderCount, 1);
return true;
}
And we get 1.3x speedup from 4 threads. Hmm, not what I expected.
Problems
I put the random state pointer in the WorkOrder struct. And it's shared across all threads.
But random number generator changes the value of the state. But writing the shared data in a thread is a dangerous thing.
As rygorous pointed at his blog:
Cores don’t like to share.
After you write shared data, other threads must throw all the work,
fetch the actual value of the variable because the cached version of data not valid anymore,
then start it's work over. This is often calling "false sharing".
So I put the random state in thread locally. So every thread writes its own random state. After implementing this simple change we get 2x speedup. Not bad!
There is another data that shared across all threads and we are writing in it.
totalBouncesComputed is a number of total bounce count that we use for measuring our program.
We are adding the number of bounces calculated on every pixel. We are doing in every sample.
I added a local variable for total bounce number, then added it to totalBouncesComputed.
Instead of incrementing hundreds of per work order, we going to do once.
After implementing this change we get 2.3x speedup. See the commit here.
Performance
Let's look at how much speed we gain from threads:
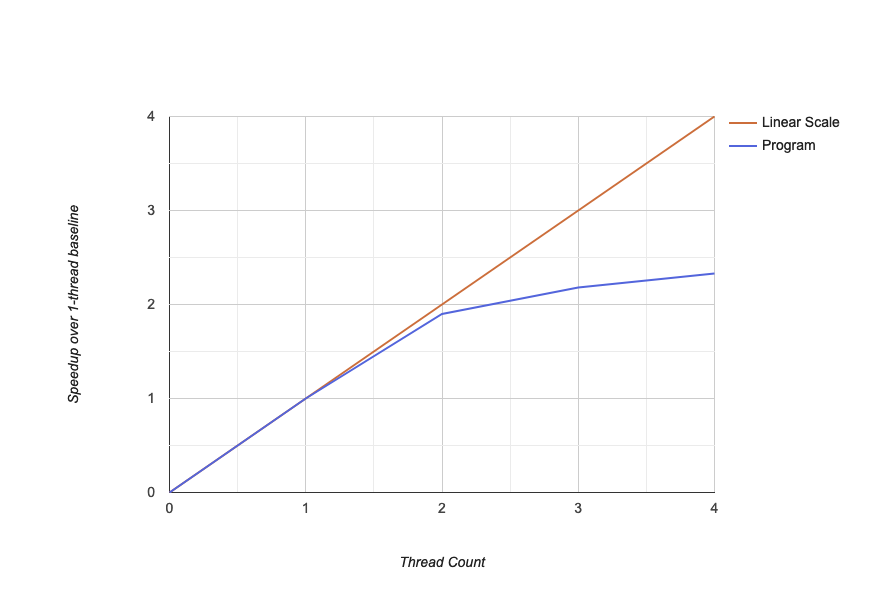
So when we use second thread, we speed up linearly, almost 2x. This makes sense on 2 core, 4 thread CPU. But we did not speed up linearly after using third and fourth thread. This means we did not gain much from hyper-threading. Honestly, I don't really know how to fine-tune and properly use of hyper-threading. So it's subject for future posts I guess.
At the end we got 49.2 Mray/s, 0.000020 ms/ray. Can we improve the performance more? I will try to using SIMD for more performance in the next post.
987 Words
2019-03-23 16:32 +0300